Introduction
When it comes to tuning a badly-performing query, there are many things that need to be checked. There may be poor query design causing the query to run slowly. There could be an issue with the underlying hardware such as CPU or IO which is bringing the performance of the query down. There could be stale statistics or missing indexes on the important columns. In short, there is not just one reason that a query can be performing poorly. Now, we can’t tune everything in just one go. But we can certainly look for one thing that would surely bring the performance of a query down – parsing of the query. This article will help you understand exactly what parsing is and how it impacts a query’s performance.
Query Processing Workflow
Before we look into what parsing is, let’s first understand the steps involved in the processing of a query. Right from the moment query is written and submitted by the user, to the point of its execution and eventual return of the results, there are several steps involved. These steps are outlined below in the following diagram.
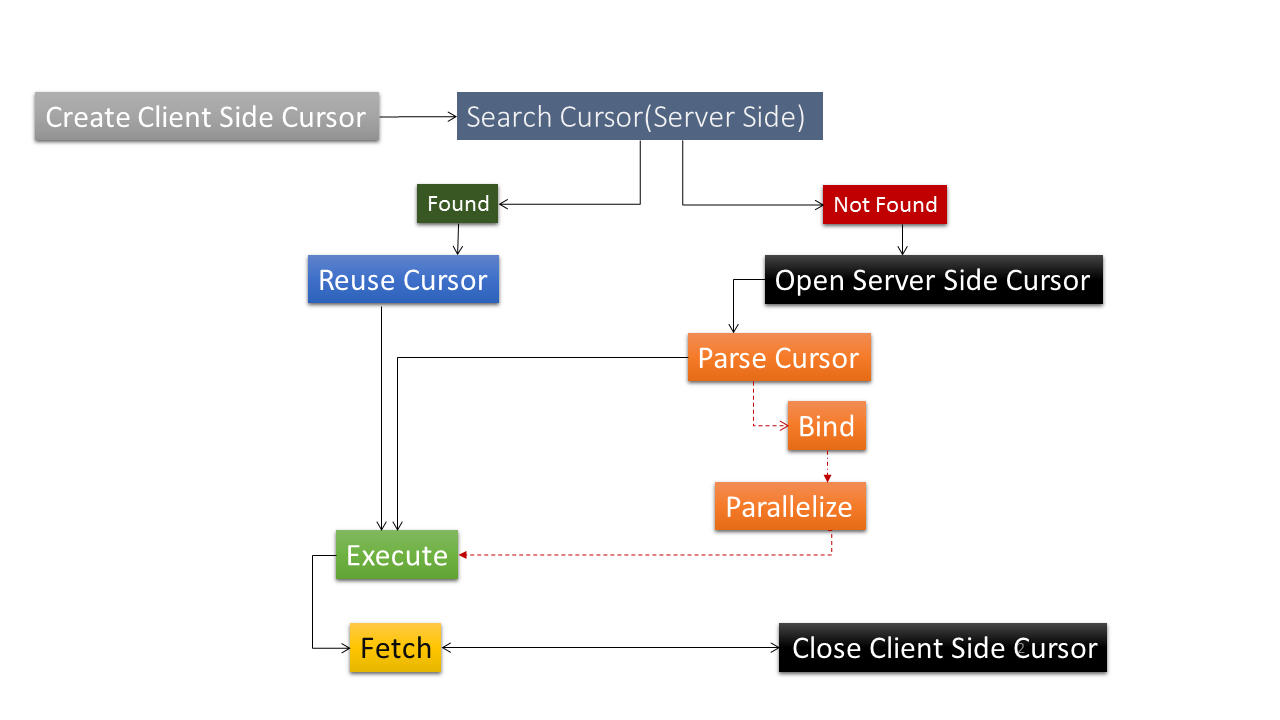
The outline of the above workflow is:
- A client side cursor is opened.
- The client’s server process searches for a shareable cursor on the server side, within the SGA’s Shared Pool memory structure.
- If the search returns a reusable cursor, it’s marked as a Hit and the next step would be to execute the cursor.
- If the cursor is not found, it’s marked as a Miss and now, a new cursor area is allocated and the parsing for this new cursor would commence.
- Once the parsing of the cursor is over, the bind variables (if used) are replaced with the actual values supplied for them.
- The query may be chosen to use parallelism, i.e. use more than one process to execute it
- One the execution of the query is complete, which results in getting the required data for the given statement, the results are fetched by the server process.
- Once the data is fetched, the cursor is closed.
In this article, we won’t be looking at details of the other steps except the parsing.
What Does Parsing a Query Mean?
A SQL statement is comprised of various inputs, i.e. different tables, functions, expressions. Thus it is possible that there are multiple ways to execute one query. Of course, the query must run in the most optimal way in order to execute in the shortest possible time. Parsing of a query is the process by which this decision making is done that for a given query, calculating how many different ways there are in which the query can run. Every query must be parsed at least once.
The parsing of a query is performed within the database using the Optimizer component. The Optimizer evaluates many different attributes of the given query i.e. number of tables involved, whether we have indexes available or not, what kind of expressions are involved, etc. Taking all of these inputs into consideration, the Optimizer decides the best possible way to execute the query. This information is stored within the SGA in the Library Cache – a sub-pool within the Shared Pool.
There are two possible states for a query’s processing information. One, that it can be found in the Library Cache and two, that it may not be found. The memory area within the Library Cache in which the information about a query’s processing is kept is called the Cursor. Thus if a reusable cursor is found within the library cache, it’s just a matter of picking it up and using it to execute the statement. This is called Soft Parsing. If it’s not possible to find a reusable cursor or if the query has never been executed before, query optimization is required. This is called Hard Parsing.
Understanding Hard Parsing
Hard parsing means that either the cursor was not found in the library cache or it was found but was invalidated for some reason. For whatever reason, Hard Parsing would mean that work needs to be done by the optimizer to ensure the most optimal execution plan for the query. The optimizer does so by looking into every possible input given to it by the user. This includes the presence (or absence) of any indexes, expressions or functions applied to the columns, whether it’s a join query or not, any hints specified etc. All of this information is of very great importance and presence or absence of any such inputs can change the execution plan.
Before the process of finding the best plan is started for the query, there are some tasks that are completed. These tasks are repeatedly executed even if the same query executes in the same session for N number of times:
- Syntax Check
- Semantics Check
- Hashing the query text and generating a hash key-value pair
Before we do anything for the query it’s important that the query’s syntax must be correct. What’s the point of trying to find the best possible way to execute the query when it can’t be executed in the first place due to a missing keyword? The database checks whether the query is written with the correct syntax or not and also whether the user executing the query has the proper permissions for the underlying objects. If either of these two checks are failed, the process of query’s execution is terminated.
Here is an example where a select statement failed to execute because the wrong syntax was used.
|
1 2 3 4 5 6 7 |
SQL> select ENAME, EMPNO, DEPTNO 2 fro SCOTT.EMP 3 where deptno=10; fro SCOTT.EMP * ERROR at line 2: ORA-00923: FROM keyword not found where expected |
As expected, the query is stopped from being executed because we (deliberately) tried to abbreviate the keyword FROM which is simply not allowed. And we are told clearly that at line #2, the keyword FROM is not found but instead it is FRO.
The syntax is checked by comparing the entire text of the query against the supported keywords for the version of the database currently in use.
The semantics check to confirm that the correct object name is used and also whether the user has the proper privileges to execute the query on the object(s) used in the statement. If this is not the case, the statement’s execution is aborted with the error ORA-00942.
|
1 2 3 4 5 |
SQL> SELECT * FROM HR.EMPLOYEES; SELECT * FROM EMPLOYEES * ERROR at line 1: ORA-00942: table or view does not exist |
If the query passes both of the above steps, the next and the most important task is to search for it in the SGA, more precisely within the Library Cache. Since it’s going to be a memory structure, the best way to search within the memory would be via the Hashing mechanism. You can read more about Hashing and the underlying algorithms used in it at http://mathworld.wolfram.com/HashFunction.html. It’s not related to Oracle database but does provide a good overview.
Oracle database takes the input of the query text and uses that to generate the hash value for the query. You can see below that even though the query executed was same apart from a change in the case of the query’s text, the generated hash values were different.
|
1 2 3 |
PARSING IN CURSOR #139822213470016 len=46 dep=0 uid=0 oct=3 lid=0 tim=1469725889630325 hv=2391634489 ad='6cbc4e80' sqlid='9nbm5yk78uwjt' select * from scott.emp where empno=7369 END OF STMT |
|
1 2 3 |
PARSING IN CURSOR #139868697312424 len=46 dep=0 uid=90 oct=3 lid=90 tim=1469726076126179 hv=1759931225 ad='81435930' sqlid='czsgw3jnfcuut' SELECT * FROM SCOTT.EMP WHERE EMPNO=7369 END OF STMT |
The previously-mentioned three tasks (syntax check, semantics check and the generation of the hash value for the query) are performed every single time, even when the query is executed in the same session N number of times.
If the given hash value and the statement text exactly match a similar statement in the library cache, the statement is termed to be executed already. This statement can now be executed as a Soft Parsed statement. But if it isn’t, the query must be Hard Parsed.
If the statement is going to be hard parsed, it means that Oracle database needs to evaluate the best possible way to execute the statement. This optimization is performed in three parts.
- Query Transformation
- Estimation
- Plan Generation
What is Query Transformation?
Query transformation is essentially the process to convert the query into a combination of simple SELECT and FROM statements. There are various transformations possible. To understand how this works, let’s pick one of the possible query transformations – Query Rewrite. This means that if Oracle finds that there is an underlying materialized view available to complete the execution of the query, the result should be fetched from it instead of going to the base tables used in the query.
In this example, we are going to create a materialized view that would be based on a simple 2-table join between the EMP and DEPT tables of the SCOTT schema.
|
1 2 3 4 5 |
SQL> create materialized view mv1 enable query rewrite 2 as select e.empno, e.ename, d.dname , d.deptno 3 from scott.emp e, scott.dept d where e.deptno=d.deptno 4 and e.deptno=10; Materialized view created. |
Since we have the materialized view available, let’s execute the query and see the execution plan used for it by Oracle.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SQL> set autot trace exp SQL> select e.empno, e.ename, d.dname , d.deptno 2 from scott.emp e, scott.dept d where e.deptno=d.deptno 3 and e.deptno=10; Execution Plan ---------------------------------------------------------- Plan hash value: 2958490228 -------------------------------------------------------------------------------- ----- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- ----- | 0 | SELECT STATEMENT | | 3 | 126 | 3 (0)| 00:00:01 | | 1 | MAT_VIEW REWRITE ACCESS FULL| MV1 | 3 | 126 | 3 (0)| 00:00:01 | -------------------------------------------------------------------------------- ----- |
As we can see, Oracle has transformed our query and it’s been executed from the materialized view. So our query, instead of being a join query processed from two tables, has transformed into a simple select accessed from a materialized view.
Another example of query transformation is Transformer Transitivity. In this, if there is an already-present condition in the query but it’s not really going to help in better performance in the execution, database may add an access path from itself that would optimize the query. An example can be seen below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SQL> select * 2 from scott.emp e, scott.dept d 3 where e.deptno=20 and e.deptno=d.deptno; Execution Plan ---------------------------------------------------------- Plan hash value: 568005898 ---------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 290 | 4 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 5 | 290 | 4 (0)| 00:00:01 | | 2 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 20 | 1 (0)| 00:00:01 | |* 3 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 | |* 4 | TABLE ACCESS FULL | EMP | 5 | 190 | 3 (0)| 00:00:01 | ---------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("D"."DEPTNO"=20) 4 - filter("E"."DEPTNO"=20) |
We can see that in this query we have added a filter on the EMP table’s DEPTNO column. As this column is a reference column from the DEPT table, it doesn’t have any index available to it. Thus there won’t be any added advantage in optimizingthis column in the execution of the query. But the DEPT tables’s DEPTNO column being a Primary Key column would surely help in limiting the search. That’s why the index available on the DEPTNO column from the DEPT table is automatically added by the optimizer in the query.
It’s important to mention that it’s not mandatory for a query to undergo any sort of transformation, but if it’s going to be applied, it must help the statement.
The next step is for the optimizer to calculate how much data (distinct values) we are looking to select from the table. This is done by calculating two values – Selectivity and Cardinality.
Selectivity is the expected amount data that should be returned from the query. The information about the column’s distinct values is calculated from the statistics stored within the data dictionary. Selectivity estimate falls in the range of 0 and 1. If histograms are used, this value is based on the density. If there are no estimates available (if the statistics are not collected), the optimizer takes help from dynamically collected statistics at the query’s runtime(using the parameter OPTIMIZER_DYNAMIC_SAMPLING).
Based on the Selectivity, Cardinality is now calculated based on the formula of, Selectivity * Total Number of Rows available in the table. This number is the estimated number of rows that we will see in the execution plan for the query.
Let’s understand this by executing a simple statement on the EMP table where we select therecord of just one employee. There are 14 rows available in the table. This means that the Selectivity estimate would be 1/14=.071428571. Now, if we multiply this value with the total number of rows in the table i.e. 14, it will return 1.
|
1 2 3 4 5 |
SQL> select (1/14)* 14 from dual; (1/14)*14 ---------- 1 |
Let’s confirm this by executing the query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SQL> select * from scott.emp where empno=7369; Execution Plan ---------------------------------------------------------- Plan hash value: 2949544139 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("EMPNO"=7369) |
Pay attention to the ROWS column. We can see that the number of rows expected by the optimizer is 1, which we know is correct.
The entire exercise in evaluating the selectivity and cardinality is to calculate the COST for executing the query. The cost of a query is an estimated number (in terms of CPU overhead) that is used by the optimizer to decide which method is the best to execute the query.
Once the cost is available, the Optimizer can now move towards the final phase of query optimization – actually trying to find the execution plan. The benchmark used is cost and the goal is to find the lowest-cost plan for the query. Depending on the complexity of the query, several alternatives may be possible. Out of all of them, the lowest cost execution plan is considered the winner and is used for the execution of the query.
Here is an example of such a comparison. What we are going to do is to trace the execution of a simple lookup from the SCOTT’s EMP table for a specific employee number. We are already aware that the EMPNO column is a Primary Key column and thus, the optimizer would prefer to use the index for this query.
Let’s generate the tracefile first.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SQL> alter session set tracefile_identifier='newt’; Session altered. SQL> alter session set events '10053 trace name context forever, level 1'; Session altered. SQL> select * from scott.emp where empno=7369; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- --------- ---------- ---------- ---------- 7369 SMITH CLERK 7902 17-DEC-80 800 20 SQL> disconn Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options SQL> exit [oracle@ocmbox trace]$ ls -l *newt* -rw-r-----. 1 oracle oinstall 87253 Aug 2 23:36 orcl_ora_2839_newt.trc -rw-r-----. 1 oracle oinstall 34190 Aug 2 23:36 orcl_ora_2839_newt.trm |
Here is an excerpt from the tracefile. We can see that the optimizer has compared the costs of both Full Table Scan and Index Scan and has declared the Index Unique Scan as the winner.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
1-ROW TABLES: EMP[EMP]#0 Access path analysis for EMP *************************************** SINGLE TABLE ACCESS PATH Single Table Cardinality Estimation for EMP[EMP] Column (#1): EMPNO( AvgLen: 4 NDV: 14 Nulls: 0 Density: 0.071429 Min: 7369 Max: 7934 Table: EMP Alias: EMP Card: Original: 14.000000 Rounded: 1 Computed: 1.00 Non Adjusted: 1.00 Access Path: TableScan Cost: 3.00 Resp: 3.00 Degree: 0 Cost_io: 3.00 Cost_cpu: 38547 Resp_io: 3.00 Resp_cpu: 38547 Access Path: index (UniqueScan) Index: PK_EMP resc_io: 1.00 resc_cpu: 8461 ix_sel: 0.071429 ix_sel_with_filters: 0.071429 Cost: 1.00 Resp: 1.00 Degree: 1 Access Path: index (AllEqUnique) Index: PK_EMP resc_io: 1.00 resc_cpu: 8461 ix_sel: 0.071429 ix_sel_with_filters: 0.071429 Cost: 1.00 Resp: 1.00 Degree: 1 One row Card: 1.000000 Best:: AccessPath: IndexUnique |
So finally, we have the plan that will be used by the database engine to execute our query!
Conclusion
Hard parsing is a necessary evil. It must happen at least once because it is the only way the optimizer can understand the best possible way to execute the query. But as we have seen above, there is so much that goes on behind the scenes when hard parsing is done. Obviously, having a query hard-parsed every time it runs would just make it slower – and that’s where Soft Parsing shines. In the next part of this series, we shall look into Soft Parsing and will understand just how it’s better compared to Hard Parsing. Stay tuned!
Load comments